Diskussion bei Alex TV
![]()
Teil 1: Was ist künstliche Intelligenz?
Inhalt
- Definition von Intelligenz IT <-> Gardner
- Unsere erste Feststellung: Ein komplexer Algorithmus
- Schwache KI Wo finden wir so etwas?
- Starke KI Warnung vor den Gefahren
- Turing Test ... kann keine starke KI messen
- Moorsches Gesetz Leistungsverdopplung alle 2 Jahre
- Hinweis auf Teil 2 Autonomes Fahren, Gefahren, Haftung, Copyright
Auch das Video zu dem Gespräch ist nun online: https://www.aktion-freiheitstattangst.org/images/videos/202505KI1-42m.mp4
und bei Youtube unter https://youtu.be/RRHqg2rgdwE
B: Seit einiger Zeit planen wir eine Sendereihe zum Thema Künstliche Intelligenz , KI, und haben dabei gesehen, dass dies viele Bereiche tangiert. Es ist bei weitem kein reines IT Thema, sondern betrifft bereits heute die Arbeitswelt, geht in die juristischen Bereiche des Copyright und der Haftung bei fehlerhafter Anwendung.
Wir beginnen einfach mal mit der Frage ...
Definition von Intelligenz
 Bild 1: Großrechner Datasaab-LA2-Itceum-D22 (CC Wikipedia) |
R: Schauen wir doch mal, wie es zu diesem Begriff kam. Das Lexikon sagt: Künstliche Intelligenz soll ein Oberbegriff sein für Methoden, die auf die Automatisierung von Entscheidungsvorgängen abzielen, die normalerweise den Einsatz menschliche Intelligenz erfordern. Erfunden hat den Begriff 1955 ein gewisser John McCarthy. Zusammen mit drei Kollegen definierte er das Wort Artifical Intelligence, AI. Das Ziel der Forscher war es herauszufinden, wie sie Maschinen dazu bringen können Sprache zu benutzen, Begriffe zu bilden und Probleme zu lösen. Also Aufgaben zu lösen die bisher den Menschen vorbehalten waren.
Dazu müssen wir uns natürlich anschauen wie Computer und ihre die Nutzung im Jahre 1955 aussahen. Die Bilder zeigen eine Datasaab-LA2-Itceum-D22 und eine IBM_704 aus dem Lawrence Livermore National Laboratory. Die Computer waren zu dieser Zeit Großrechner. Sie konnten Tabellen aufstellen und Tabellen auswerten und auch ganz primitiv Textverarbeitung ausführen. Möglich war also das Sortieren von zum Beispiel Namens- oder Rechnungslisten oder ein Wörterbuch zu erstellen.
 Bild 2: IBM_704 aus dem Lawrence Livermore National Laboratory (CC Wikipedia) |
B: Niemand würde auf den Gedanken kommen ein Tabellenverarbeitungsgerät oder eine Sortiermaschine als intelligent zu bezeichnen. Selbst wenn sie Sprache benutzen kann, wenn sie Begriffe bilden kann und Probleme lösen kann, mag dies vielleicht für einen Menschen aus dem Bereich der IT intelligent sein.
R: Ja, wenn wir genauer hinschauen, so sehen wir, dass
- das Problem bekannt ist,
- eine Frage formuliert werden kann,
- ein Algorithmus aufgestellt werden kann, der eine Antwort errechnet aufgrund der vorhandenen Daten.
B: Da fällt mir das schöne Beispiel aus dem Film "Per Anhalter durch die Galaxis" ein. Dort wird der "alles wissende Computer" nach der Antwort auf die grundlegende Frage des Universums gefragt und seine Antwort ist 42.
R: Wir sehen also jetzt, was eine künstliche Intelligenz braucht: (Bild03 folgende Liste)
- Eine Frage muss da sein.
- Ein großer Haufen an Daten muss vorliegen über dieses Problem.
- Dann kann eine Antwort errechnet werden.
- Es ist also eine Suche in vorhandenen Wissen.
B: Wir müssen uns also die Frage stellen: ist die Suche in vorhandenem Wissen und die Fähigkeit dazu bereits Intelligenz?
Schauen wir uns die Definition von Intelligenz an. Aus dem Bereich der IT finden wir folgende Definition von Intelligenz.
R: Eine Definition des Begriffs Intelligenz (aus dem Bereich der IT):
Intelligenz zeigt sich ganz allgemein durch zielgerichtete Wahrnehmung (menschlich) der Umgebung, vernünftiges – das muss näher definiert werden - Denken und – das ist im Gehirn nicht gleichbedeutend mit dem was in Rechnern geschieht -, welches autonomes Lernen – das kann an Emotionen gebunden sein - und Problemlösen mit einschließt, sowie zweckorientiertes Handeln, zu welchem auch die Kommunikation – beim Rechner stark eingeschränkt nur aus 0 und 1 besteht - von und zwischen Intelligenzträgern – wollen wir als Mensch so genannt werden? - gehört.
B:: Nein, das ist nicht alles was zur Intelligenz gehört, denn Maschinen können mit Menschen nicht in dieser Art und Weise verglichen werden. Z.B. ist Wahrnehmung als Begriff für eine menschliche Eigenschaft nicht zu vergleichen mit einer maschinellen Eigenschaft.
Der US Psychologe Howard Gardner beschrieb in den sechziger Jahren die vielfältigen Facetten des Begriffs Intelligenz. Er entwickelte eine Theorie der Begabungen und seine Beschreibung von Intelligenz geht weit über den einer künstlichen Intelligenz hinaus. Er beschrieb dabei ein breites Spektrum von Ausprägungen der Intelligenz. So zum Beispiel
- die sprachliche Begabung,
- die musikalische Intelligenz,
- das Einfühlungsvermögen,
- das Vermögen zu besonderen Bewegungsabläufen,
- die körperliche Feinmotorik,
- die Intelligenz zu logischen Schlussfolgerungen,
- die Raumorientierung (Geometrie) und ihre Nutzung im täglichen Leben,
- die interpersonelle Intelligenz, auch als Empathie bezeichnet,
- den Sinn für Familie und Freunde (Community),
- die Fähigkeit eigene Gefühle und deren Grenzen zu verarbeiten,
- eine naturelle Intelligenz, die ein Naturverständnis einschließt,
- die existenzielle Intelligenz, die grundsätzliche Fragen und Grenzfragen des Lebens hinterfragt.
Auf jeden Fall sind seine Beschreibungen und die von dem deutschen Psychologen Stemberg benutzten eher geeignet die menschliche Intelligenz zu beschreiben als die oben verwendete doch sehr einseitige Beschreibung aus dem Bereich der IT. Diese umfasst aus der Liste von Gardner gerade mal die logischen Schlussfolgerungen und die Raumorientierung.
Zur Wahrnehmung und zum Denken, also den Grundlagen für Intelligenz gehören also weitere menschliche Eigenschaften, wie Emotion, Intellekt, Intuition und die stehen für das Menschsein ganz oben. Außerdem noch Lernen und Kommunikation, nur dann kann eine Problemlösung gelingen.
Unsere erste Feststellung:
Der Intelligenzbegriff aus der IT ist nicht angemessen für die Beschreibung einer Maschine. John McCarthy müsste seine Maschine anders nennen. Passender als künstliche Intelligenz wäre komplexer Algorithmus.
Was ist von solchen komplexen Programm derzeit zu erwarten? Was können Sie und was nicht?
R: Auch ein KI-Programm muss den Algorithmus, also den Lösungsweg stets in einer Programmiersprache beschreiben. Die Programmiersprachen haben sich über die letzten 50 Jahre ständig weiter entwickelt und sind komplexer geworden.
Ein Blick in die Computer-Historie
Eigentlich kann der Computer – früher aufgebaut aus mechanischen Relais, die Strom weiterleiten konnten oder nicht, also 1 oder 0, nicht viel. In den 50-iger Jahren wurde die Relais dann aus kleineren und vor allem schnelleren Elektronenröhren, in den 60-iger Jahren durch Transistoren, später integrierten Schaltkreisen ersetzt. Auch die konnten nichts außer 0 und 1 hin und her zu schieben und Zahlen zu addieren. Die seit den 40-iger Jahren gleich gebliebene Schaltung ist der sogenannte Halbaddierer (Bild04 Halbaddierer.gif).
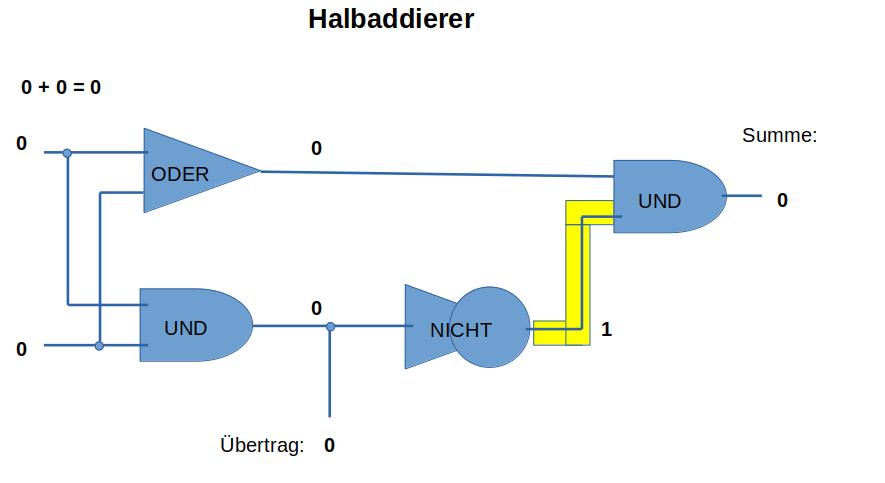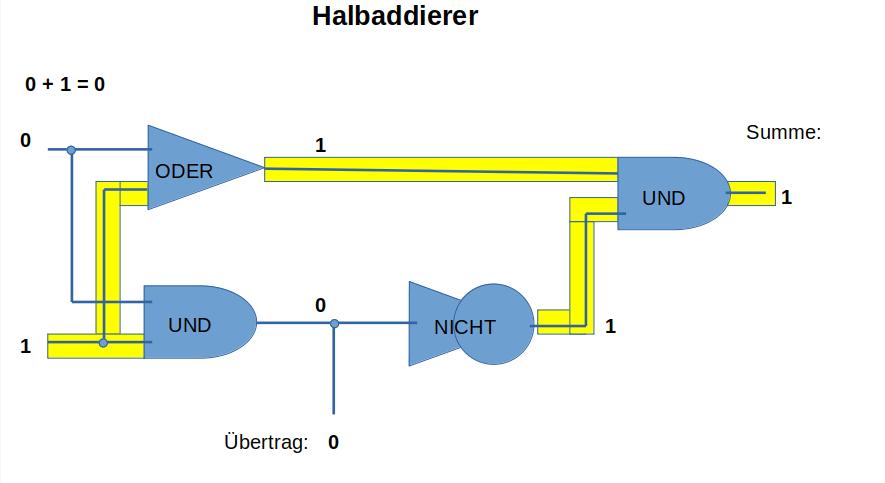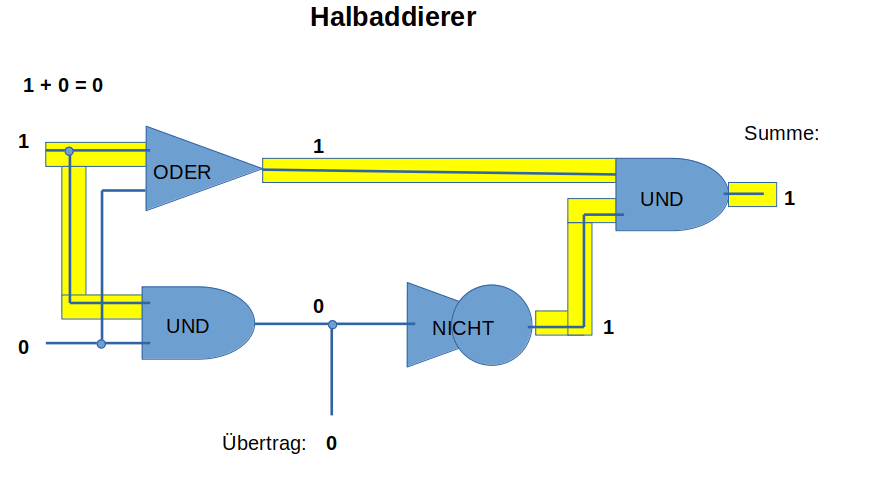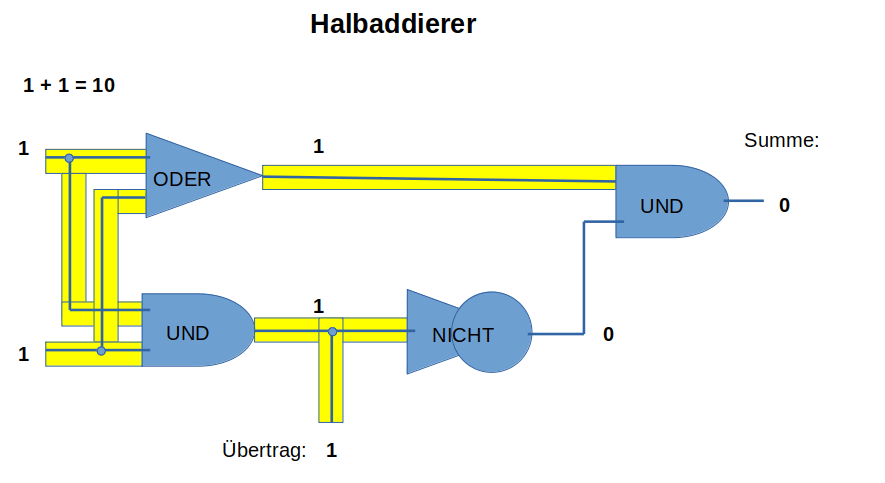 Bild 4: Halbaddierer mit Hilfe von 3 verschiedenen Logikbausteinen |
Wir wollen 0 und 1 addieren, das sind nur 4 mögliche Aufgaben: 0+0=0 1+0=1 0+1=1 und 1+1=10 , letzteres heißt wir haben einen Übertrag in die nächste Stelle erhalten, so wie wir es in unserem Zehnerzahlensystem erleben, wenn wir 9+1=10 berechnen.
Um das automatisch zu berechnen, brauchen wir dazu 3 verschiedene Relais, die am Ausgang
- Spannung anzeigen, wenn an beiden Eingängen Spannung anliegt, ein UND-Baustein,
- Spannung anzeigen, wenn einer der beiden Eingänge Spannung bekommt, ein ODER-Baustein,
- keine Spannung anzeigt, wenn am Eingang Spannung anliegt, ein NICHT-Baustein.
Wenn wir die dann in der links abgebildeten Schaltung anordnen, habe wir einen Halbaddierer, mit dem wir die zwei Ziffern (0 und 1, mehr kennt der Computer nicht) addieren können. Bei der Addition von 1+1 erhalten wir dann eine 0 und eine 1 als Übertrag für die nächst höhere Stelle der Zahl. Mehr kann ein Computer eigentlich nicht. Das "mehr" was wir heute sehen, ist der Tatsache geschuldet, dass inzwischen in einem Rechner viele Halbaddierer zusammen geschaltet und die Programme komplexer geworden sind.
Es braucht dann also viele davon um große Zahlen zu addieren und inzwischen noch viele Milliarden mehr an Speicherplätzen, wo diese Zahlen abgelegt werden. Und ein Programm muss dem Computer sagen was zu tun ist. Es begann einmal mit Assembler, einer Maschinensprache, die wie hier in diesem kleinen Buch beschrieben aus 256 Befehlen bestand. Damit musste man sein Programm beschreiben, um zu einem Ergebnis zu kommen. (Bild05 Befehlssatz8080.jpg)
256 verschiedene Befehle hört sich viel an, es sind im wesentlichen jedoch nur Speicher-Verschiebebefehle, Addition und Subtraktion (Bild06 8080-Subtraktion.jpg) und die Möglichkeit im Programm je nach Stand der Berechnung an bestimmte Stellen im Programmcode zu springen. Solche Verzweigungen erlauben es dann Vorgänge in Schleifen zu wiederholen – etwas was ein Computer gut und schnell kann.
In den achtziger und neunziger Jahren wurden die Programmiersprachen der menschlichen Sprache ähnlicher. Dafür musste der Computer die Befehle vor der Ausführung erst aus den so genannten höheren Programmiersprachen wieder zurück in seinen Maschinen-Code übersetzen, um ihn auszuführen.
Es blieb aber im wesentlichen bei den oben beschriebenen Fähigkeiten, Inhalte von Speicherplätzen zu verschieben, zu addieren und zu verzweigen. Erst in den späten neunziger Jahren war es üblich, dass Programme auf Ereignisse (Events) reagieren konnten. Das waren zum Beispiel ein Mausklick, die Temperatur des Prozessors, eine Außentemperatur oder andere Sensoren, die für seine Arbeit wichtig waren.
Wenn wir nun davon ausgehen, dass das Programm auf die Eingaben eines Mikrofons, also Sprache, oder sogar auf die Eingaben einer Kamera, also Bilder oder Videos reagieren kann, dann können wir uns fragen ...
B: Was ist von solchen Programm derzeit zu erwarten und was nicht und was eventuell in späterer Zukunft?
 Bild 6: Alexa, ein Cloud-basierter Sprachservice von Amazon |
R: Wir suchen zuerst einmal eine genauere Unterscheidung in dem Begriff künstlicher Intelligenz. Das führt uns zu den Begriffen starke und schwache künstliche Intelligenz.
Schwache KI:
Die so genannte schwache KI haben wir wahrscheinlich alle schon einmal erlebt. Das sind Alexa (Bild07 Alexa.gif), Siri und der Google Assistent, sie gehören zur Kategorie der schwachen KI und wir können mit ihnen sprechen, sie hören uns jederzeit(!) zu und sie antworten uns mehr oder weniger sinnvoll.
Noch ein wenig komplexer wird es beim Übersetzen in andere Sprachen, bei der Bilderkennung oder der Bildgenerierung. Die beiden letzten Begriffe haben leider auch ihre Verwendung bei der Zielerkennung oder Zielgenerierung, also im militärischen Bereich gefunden. Dazu muss das System zuerst mit vielen Daten auf seine Aufgabe trainiert werden. Es verfügt dann über ein Large Language Model (LLM) und kann damit arbeiten, versagt aber, wenn es zu Problemen außerhalb dieses Modells befragt wird.
Was kann also eine schwache KI?
Mit ihr können klar definierte Aufgaben mit einer festgelegten Methodik bewältigt werden, um dabei durchaus komplexe aber wiederkehrende und genau spezifizierte Probleme zu lösen. Die besonderen Vorzüge der schwachen KI liegen in der Automatisierung und im Controlling, also dem Überwachen von Prozessen.
Diese schwache KI, die man auch als methodisch KI bezeichnet, besitzt keine Kreativität und keine expliziten Fähigkeiten selbstständig zu lernen. Ihre Lernfähigkeiten ist auf das Trainieren von Erkennungsmustern oder das Abgleichen und durchsuchen von großen Datenmenge reduziert. Man bezeichnet so etwas auch als Machine Learning.
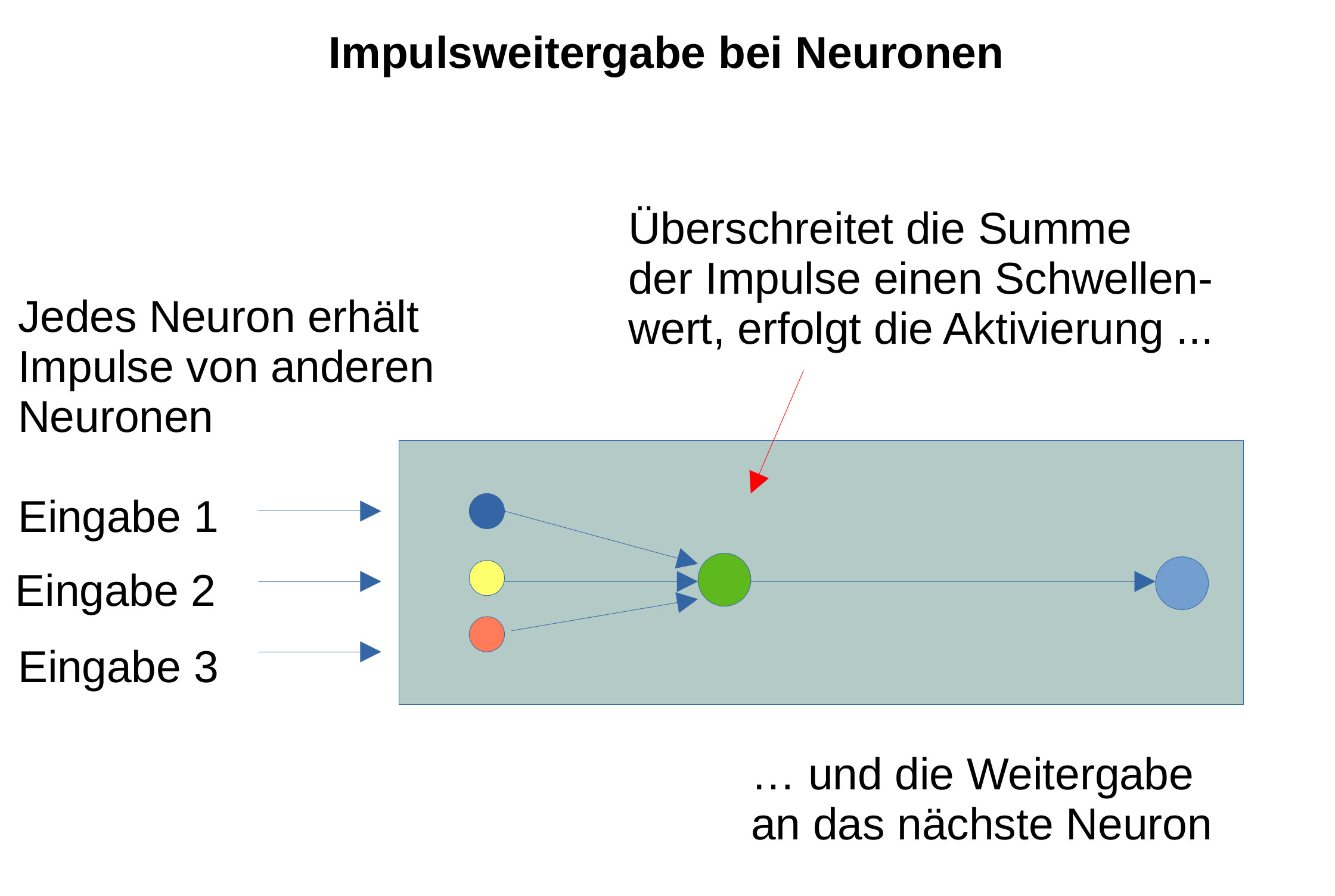 Bild 7: Impulsweitergabe bei einem künstlichen neuronalen Netzwerk |
Dieser Begriff taucht auch in den Ehrungen der diesjährigen Nobelpreisträger in Physik und Chemie auf. Hopefield und Hinton erhalten den Nobelpreis in Physik für die Entwicklung künstlicher neuronaler Netze – dem menschlichen Gehirn nachempfunden - mit Milliarden von Knoten (Bild 7: NeuronenRechnen.pdf). Das haben sie vor etwa 20 Jahren bereits begonnen.
Künstliche neuronale Netzwerke, KNN
KNN wurden von den Netzwerken inspiriert, die biologische Neuronen in unseren menschlichen Gehirnen bilden. Biologische Neuronen sind miteinander vernetzt und in Schichten organisiert. Sie können mehrere Eingangssignale aufsummieren und geben nur dann ein Signal an andere Neuronen weiter, wenn die Summe der Eingangssignale einen Schwellenwert erreicht. Unser Gehirn rechnet also nicht mit 0 und 1, sondern kann Entscheidungen viel feiner abstufen. (Bild08 NeuronenRechnen.pdf)
Den Nobelpreis in Chemie teilen sich David Baker, Demis Hassabis und John Jumper. Auch sie haben sich mit KNN beschäftigt. Die beiden Letztgenannten arbeiten bei Google Deepmind und haben dort mit Hilfe von KI komplexe Protein-Strukturen für mögliche Medikamente modelliert und auch inzwischen im Körper gefundene Proteine als "möglich" vorhergesagt.
Auch wenn man mit dem Begriff "schwach" in Richtung "gering" denken mag, so ist doch die Rechenleistung für diese Aufgaben enorm. Wir kommen später noch zu dem Energie- und Arbeits-Aufwand den man treiben muss, um solche Aufgaben gut zu lösen.
Starke KI:
Eine wirklich starke KI gibt es noch nicht.
B: Was wäre eine? Was erwartet man von einer? Worauf arbeitet man hin?
 Bild 8: Unterschiede starke und schwache KI |
R: Eine starke KI muss selbstständig eine Aufgabenstellung erkennen und definieren können und sich hierfür selbstständig das Wissen aus dieser entsprechenden Anwendungsdomäne erarbeiten und aufbauen können. Dann muss sie die vorhandenen Probleme untersuchen und analysieren, um zu einer adäquaten Lösung zu kommen. Und diese Lösung sollte dann auch neu und kreativ sein.
Bei diesen hohen Anforderungen ist es klar, dass wir von einer starken KI noch weit entfernt sind.
Eine starke KI muss nach den Anforderungen der Technischen Hochschule Würzburg-Schweinfurt die auf der links nebenstehenden Tabelle genannten folgenden Schritte beherrschen: (Bild09 StarkeKI-THWS.png Quelle Hochschule: Unterschiede starke und schwache KI)
Da eine starke KI noch nicht existiert, können wir über die folgende Warnung noch (!) lächeln.
Warnung:
So sagt der KI-Forscher Yuval Noah Harari: Bei der (starken) KI handelt es sich um die erste Technologie in der Geschichte, die selbstständige Entscheidungen treffen kann. Und nicht nur das: Eine solche KI kann aus sich selbst heraus neue Ideen entwickeln. Jeder Mensch sollte verstehen, was das bedeutet. Diese KI ist kein Werkzeug, sondern ein Akteur.
- KI kann zu finanziellen, politischen und sozialen Krisen führen, mit denen wir bisher nicht gerechnet haben.
- Paranoiden Diktatoren ist es zuzutrauen, dass sie einer KI die Kontrolle über ihre Atomwaffen einräumen.
- KI kann die beste Strategie aushecken, ein Virus über Flughäfen oder die Lebensmittelversorgung global zu verbreiten.
- In Kriegen wird es nun immer häufiger eine KI sein, die darüber entscheidet, welche Ziele angegriffen werden sollen.
B:: Wie können wir erkennen, ob sich eine KI zu einer "starken" entwickelt oder entwickelt hat?
R: Jahrelang hat man sich auf den Turing Test verlassen.
Auf Wikipedia finden wir den sogenannten Turing Test erklärt: Bereits im Jahre 1950 formulierte Alan Turing eine Methode, um festzustellen, ob ein Computer oder eine Maschine ein den Menschen gleichwertiges Denkvermögen aufweist. Dazu muss ein Mensch mit dem Computer kommunizieren und soll dabei erkennen, ob es sich um einen Computer oder einen hinter dem Bildschirm versteckten Menschen handelt.
B: Inzwischen ist der Turing Test auch in der Kritik, weil es bei ihm in erster Linie darum geht, den davor sitzenden Menschen zu täuschen. Er zeigt eigentlich nur, bei welchem Verhalten (einer Maschine) sich Menschen dieses etwas als intelligent vorstellen.
R: Die Ergebnisse sind trotzdem interessant:
Am 3. September 2011 nahm das kleine Programm CleverBot mit echten Menschen an einem Turing Test am indischen Institut IIT Guwahati teil. 59 % der 1334 Menschen hielten Cleverbot für einen Menschen. Auch diverse Schach Computer haben bereits Schachweltmeister geschlagen. Und bei dem Spiel GO ist das passiert:
Bemerkenswert am Sieg von AlphaGo über Lee Sedol war nicht nur die Tatsache, dass die KI gewann. Sondern die Art und Weise, wie sie gewann. AlphaGo verwendete eine Strategie, die uns Menschen völlig fremd war. Kein Mensch wäre jemals auf die Idee gekommen, einen solchen Zug zu spielen, wie AlphaGo es tat. Alle Zuschauer dachten, dass dies ein schrecklicher Fehler der KI gewesen sei.
Grenzen zu überschreiten, kann positiv sein. Ja, in Spielen wie Go, aber ...
Wie wird die Entwicklung weitergehen?
Bild 9: Das Mooresche Gesetz (1970-2020Wikipedia CC) |
Das Mooresche Gesetz (Bild 9: Moores_Law_Transistor_Count 1970-2020WikipediaCC.png) sagt bei der Entwicklung der IT eine zweijährliche Verdopplung der Rechenleistung voraus. Allerdings kann das nicht unendlich so weitergehen. Inzwischen stößt man bei der Herstellung der immer kleineren Chips und damit dem Wachstum der Anzahl der Schaltkreise an physikalische Grenzen. 2016 verstieg man sich dieser Aussage: Man baut jetzt (der Wikipedia Artikel ist von 2016) Chips mit einem Leitungsabstand von 14 nm. Das sind dann 14*10⁻9m. Spätestens, wenn man in den Bereich von 2-3 nm kommen würde, werden diese Chips Rechenfehler erzeugen, weil in diesem Bereich bereits quantenphysikkalische Tunnelströme auftreten.
Nun hat die chinesische Firma Xiaomi einen eigenen 3nm-Chip entwickelt, dessen Massenproduktion für 2025 geplant ist und wohl fehlerfrei rechnet. Trotzdem werden wir demnächst an diese physikalische Grenze stoßen.
Spätestens dann muss man über andere Computer-Architekturen nachdenken, was uns sicher irgendwann zu einem Quantencomputer (Bild12 Quantencomputer2.jpg + Bild13 Quantencomputer2.jpg) führen würde, weil diese statt mit Strom (Elektronen) mit Licht (Photonen) arbeiten. Man kann bereits Modelle aus China kaufen, allerdings sind die dafür notwendigen Programmiersprachen noch in der Entwicklung. Und es gibt durchaus verschiedene Ideen, wie man auf die Möglichkeiten solcher Geräte zugreift.
Mit masselosen Photonen lässt sich viel schneller arbeiten als den "großen" Elektronen. Google behauptete kürzlich: sein Chip mit 53 supraleitenden Qbits sollte in 200 Sekunden eine Aufgabe gelöst haben, für die ein Supercomputer 10.000 Jahre gebraucht hätte. Wenige Tage später folgte die Ernüchterung: Der Konkurrent IBM zeigte, dass ein Supercomputer diese Aufgabe mit den richtigen Methoden in nur 2,5 Tagen lösen kann. Das wäre "nur noch 1080-mal schneller", aber verglichen mit dem Moore’schen Gesetz wären das doch mehr als 20 Jahre "Fortschritt" (1024=2^10).
B: Damit wollen wir den Einstieg in das Thema KI für heute abschließen und versprechen, dass die weiteren Teile nicht so tief in die Computertechnik einsteigen werden. Wir haben gelernt, dass Computer außer addieren und Inhalte von Speicherplätzen verschieben nichts können – aber das dafür sehr schnell. Erst durch die Programme erlangen sie weitere Fähigkeiten.
Im nächsten Teil wollen wir darauf eingehen, wie groß die Gefahren, z.B. beim autonomen Fahren sein können, was die EU mit ihrem AI-Act/KI-Act erreichen will und was uns das bei Fragen der Haftung für fehlerhaftes Verhalten von KI gesteuerten Geräten bringt und was beim Copyright bei KI-generierten Texten und Bildern zu beachten ist.
Am Ende wird sich dann Teil 3 mit den vielfältigen ethischen Fragen auseinandersetzen ...
Mehr dazu in allen unseren Artikeln zum Thema KI https://www.aktion-freiheitstattangst.org/cgi-bin/searchartl.pl?suche=künstliche&sel=meta
und das Video zu dieser Sendung von AlexTV im Offenen Kanal Berlin wird hier verlinkt sobald es verfügbar ist.
Teil 2 unserer Sendereihe beschäftigt sich mit den Gefahren von KI, z.B. beim autonomen Fahren und untersucht dann Fragen der Haftung und des Urheberrechts https://www.aktion-freiheitstattangst.org/de/articles/9013-20241230-thema-kuenstliche-intelligenz.html
Kategorie[26]: Verbraucher- & ArbeitnehmerInnen-Datenschutz Short-Link dieser Seite: a-fsa.de/d/3Dz
Link zu dieser Seite: https://www.aktion-freiheitstattangst.org/de/articles/8950-20241031-thema-kuenstliche-intelligenz.htm
Link im Tor-Netzwerk: http://a6pdp5vmmw4zm5tifrc3qo2pyz7mvnk4zzimpesnckvzinubzmioddad.onion/de/articles/8950-20241031-thema-kuenstliche-intelligenz.htm
Tags: #KI #AI-Act #EU #Intelligenzbegriff #Computerhistorie #Algorithmen #LargeLanguageModel #LLM #NeuronaleNetze #KNN #Turingtest #MooresGesetz #Verbraucherdatenschutz #Datenschutz #Datensicherheit #Datenpannen #Datenskandale #Transparenz #Informationsfreiheit #AlexTV #Video #Transkript
Erstellt: 2024-10-31 08:22:14 Aufrufe: 1008
Kommentar abgeben



